Abstract
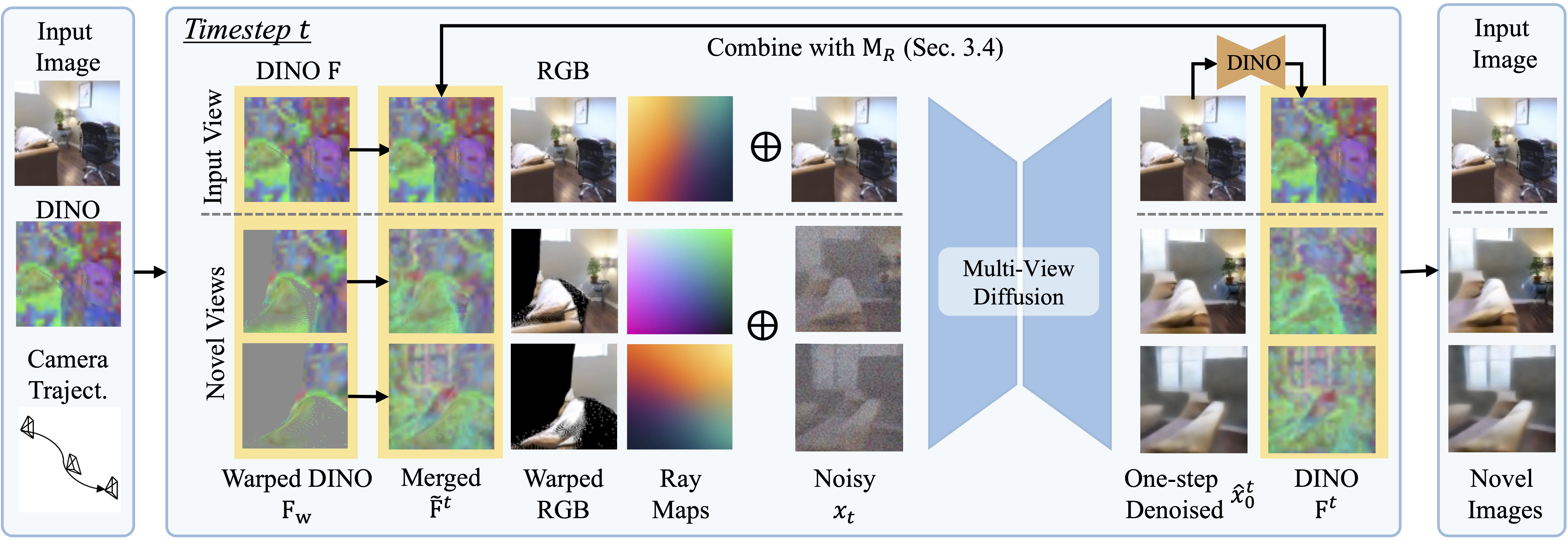
We present SemanticNVS, a camera-conditioned multi-view diffusion model for novel view synthesis (NVS), which improves generation quality and consistency by integrating pre-trained semantic feature extractors.
Existing NVS methods perform well for views near the input view, however, they tend to generate semantically implausible and distorted images under long-range camera motion, revealing severe degradation. We speculate that this degradation is due to current models failing to fully understand their conditioning or intermediate generated scene content. Here, we propose to integrate pre-trained semantic feature extractors to incorporate stronger scene semantics as conditioning to achieve high-quality generation even at distant viewpoints. We investigate two different strategies, (1) warped semantic features and (2) an alternating scheme of understanding and generation at each denoising step. Experimental results on multiple datasets demonstrate the clear qualitative and quantitative (4.69%-15.26% in FID) improvement over state-of-the-art alternatives.